7.1 SVM
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
7.1.1 SVM 基本概念
将实例的特征向量(以二维为例)映射为空间中的一些点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
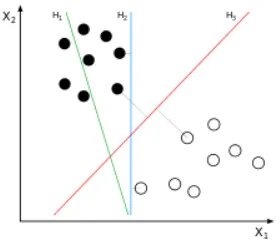
Q1:能够画出多少条线对样本点进行区分?
答:线是有无数条可以画的,区别就在于效果好不好,每条线都可以叫做一个划分超平面。比如上面的绿线就不好,蓝线还凑合,红线看起来就比较好。
Q2:为什么要叫作“超平面”呢?
答:因为样本的特征很可能是高维的,此时样本空间的划分就不是一条线了。
Q3:画线的标准是什么?/ 什么才叫这条线的效果好?/ 哪里好?
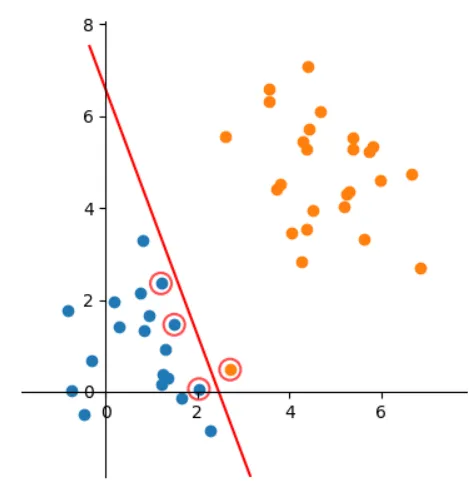
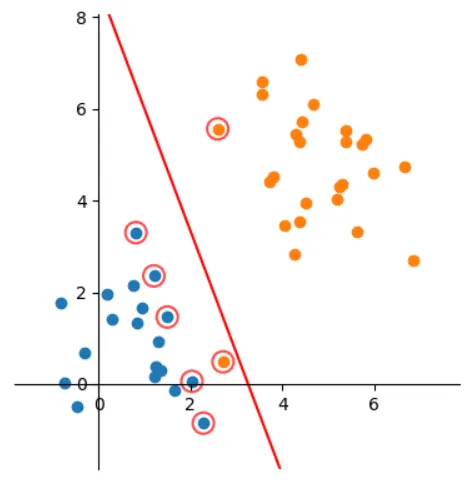
答:SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。
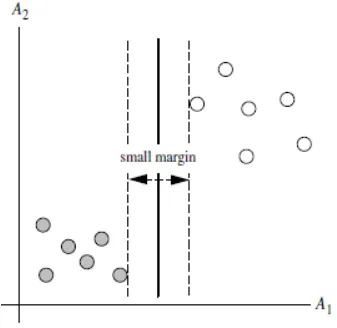
Q4:间隔(margin)是什么?
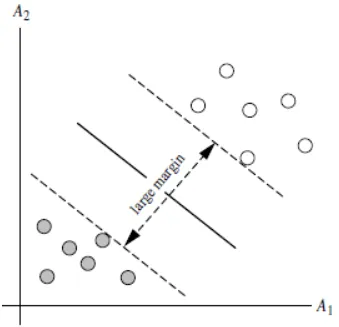
答:对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比如下图中两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。但此时 margin 比较小,如果用第二种方式画,margin 明显变大也更接近我们的目标。
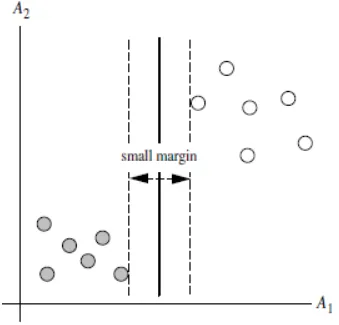
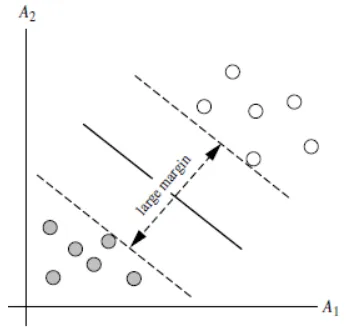
Q5:为什么要让 margin 尽量大?
答:因为大 margin 犯错的几率比较小,也就是更鲁棒。
Q6:支持向量是什么?
答:从上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。
7.1.2 hard-margin SVM
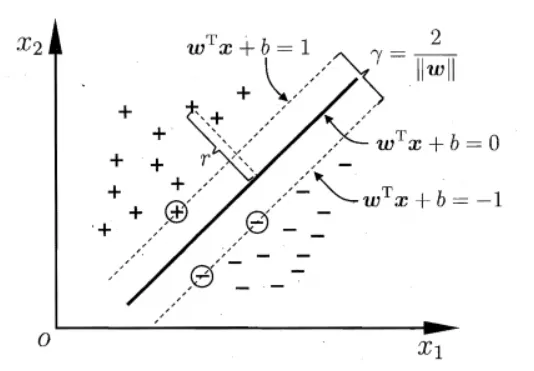
寻找最大间隔:
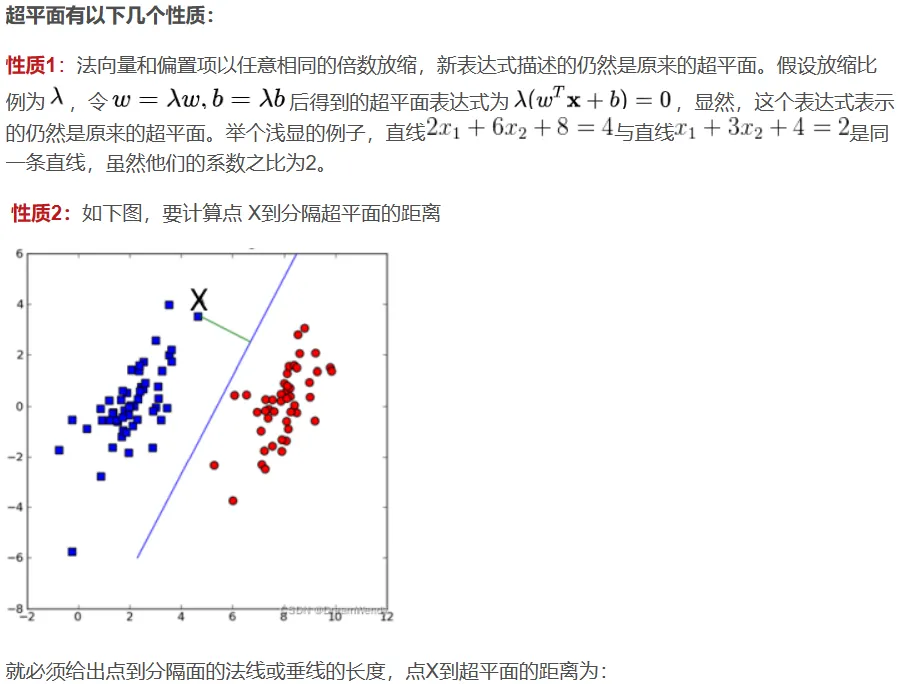
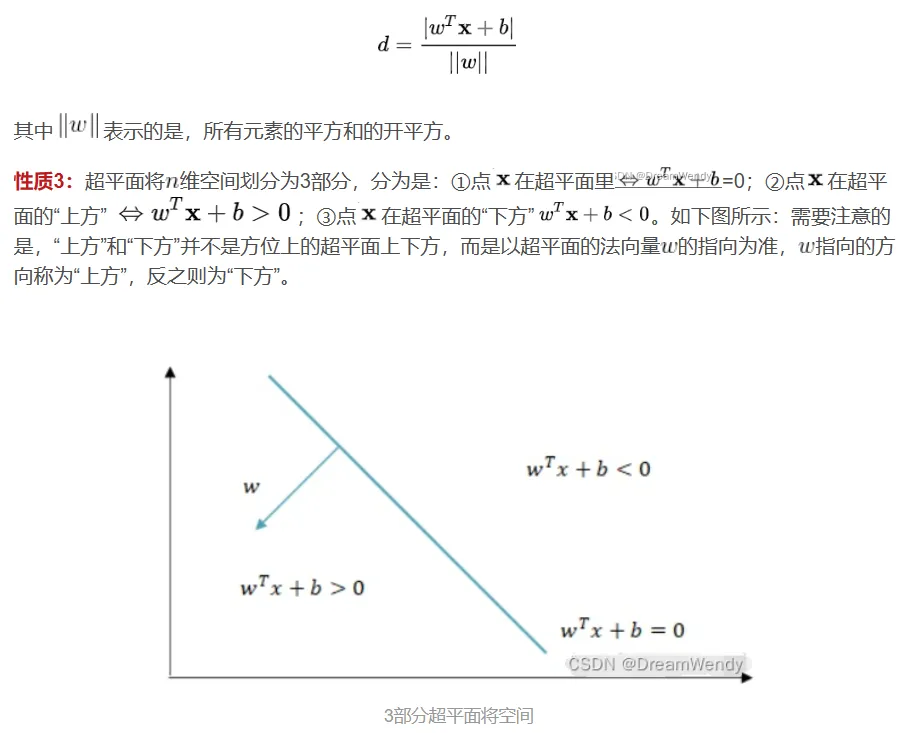



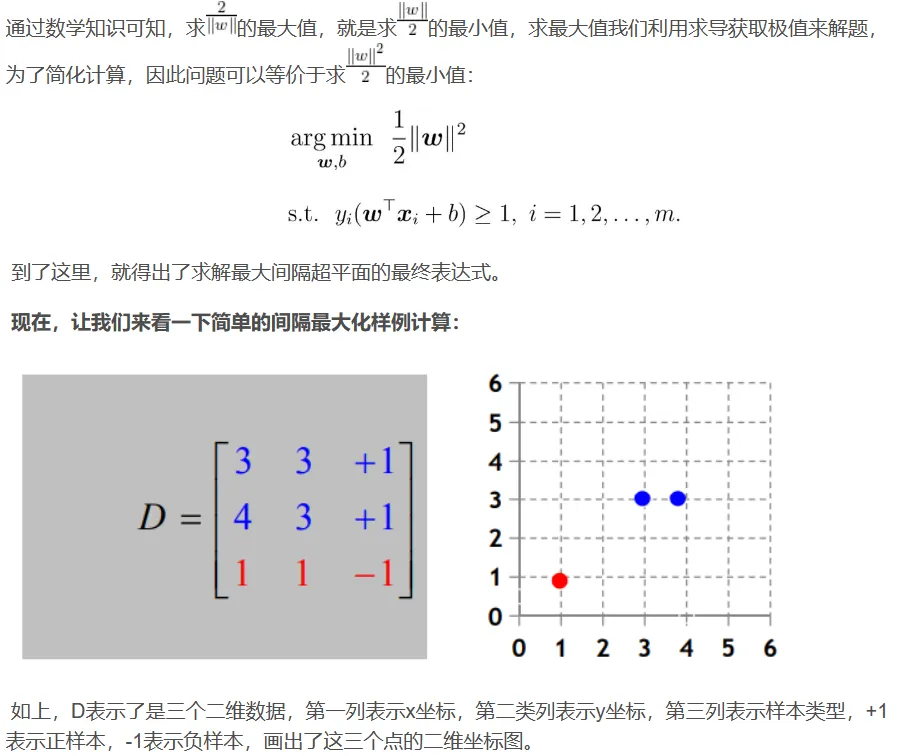
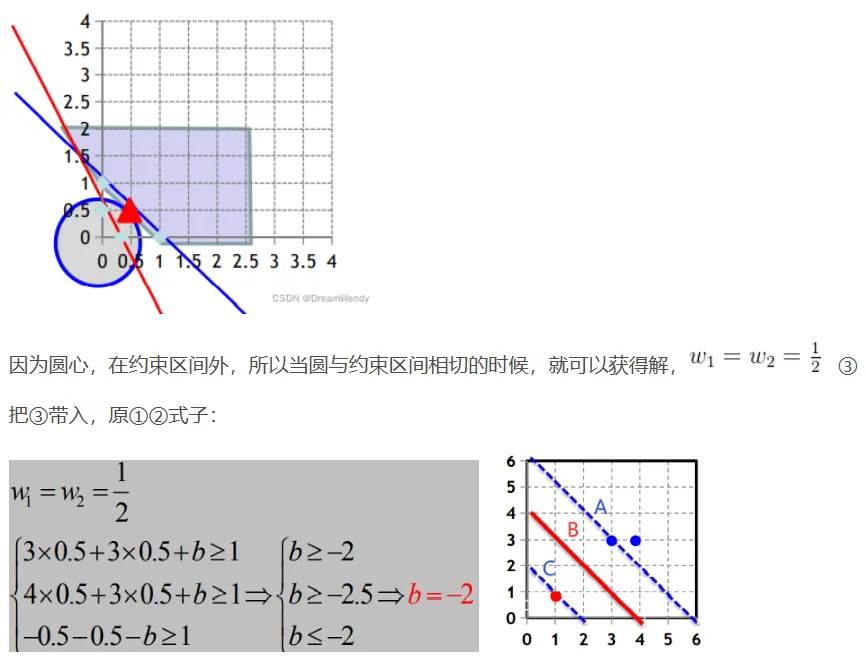
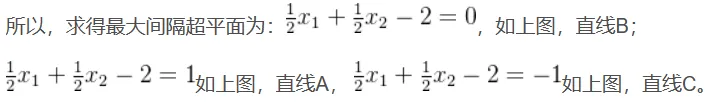






![]()

7.2 核方法
使用核方法的动机
在线性 SVM 中转化为最优化问题时求解的公式计算都是以内积(dot product)形式出现的,其中 是把训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂度非常大,所以我们利用核函数来取代计算非线性映射函数的内积。以下核函数和非线性映射函数的内积等同,但核函数 K 的运算量要远少于求内积。
![]()

使用 kernel 的意义在于:
- 将向量的维度从低维映射到高维
- 降低运算复杂度降低运算复杂度
线性可区分和线性不可区分
能够用一条直线对样本点进行分类的属于线性可区分(linear separable),否则为线性不可区分(linear inseparable)。
以下三个例子,都是线性不可区分的,即无法用一条直线将两类样本点区分开。
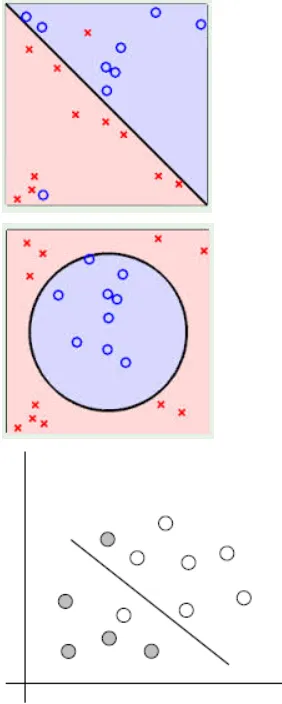
而刚才的例子就是线性可区分的。
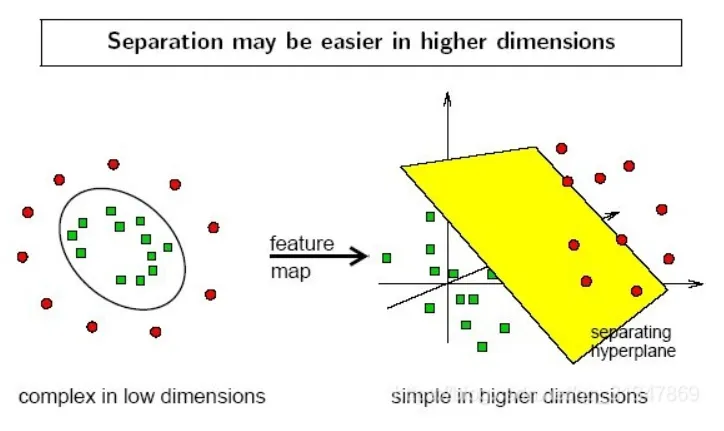
在线性不可分的情况下,数据集在空间中对应的向量无法被一个超平面区分开,如何处理?
:两个步骤来解决:
- 利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中(比如下图将二维空间中的点映射到三维空间)
- 在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理
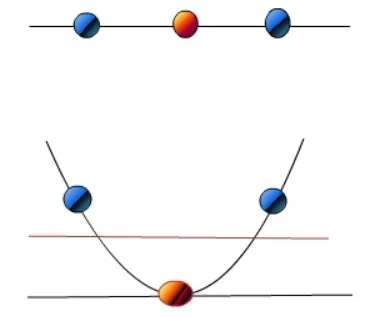
比如想要将红点和蓝点变成线性可分的,那么就将映射 y = x变成映射 y=x^2 ,这样就线性可分了。
7.3 序列最小最优算法(sequential minimal optimization)
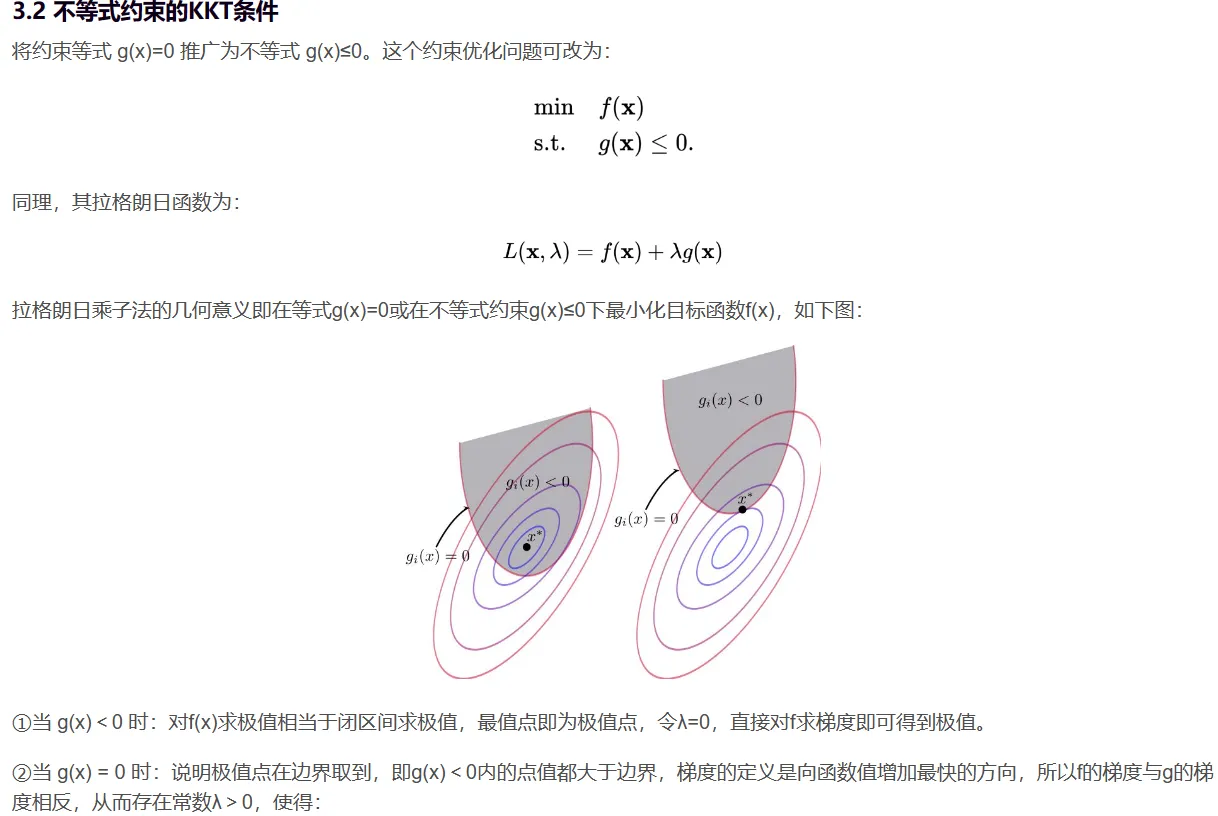
SMO算法是一种启发式算法,其基本思路是:如果所有变量的解都满足此优化问题的KKT条件,那么这个最优化问题的解就得到了。(KKT条件是该最优化问题的充分必要条件)。否则,选择两个变量,固定其他变量针对这两个变量构建一个二次规划问题。

特点:
将原始的二次规划问题分解为只含有两个变量的二次规划子问题,对子问题不断求解,使得所有的变量满足KKT条件
包含两部分:
1、求解两个变量二次规划的解析方法
2、选择变量的启发式方法
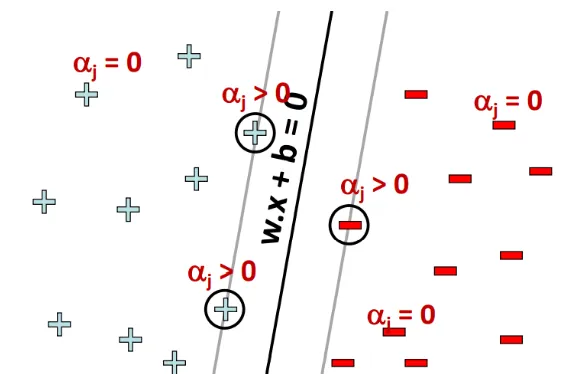
(1)第1个变量的选择:确定在当前的分类器中,违反KKT条件的元组Xi;
SMO称第1个变量的选择称为外循环。外循环在训练样本中选取违反KKT条件最严重的样本点,将其作为第一个变量。遍历的时候首先遍历满足的样本点,也就是在间隔边界上的支持向量点,检验是否满足KKT条件;如果都满足,那么遍历整个训练集,检验是否满足KKT条件。
(2)第2个变量的选择:根据Xi,找到使得|Ei−Ej|最大的元组Xj;
SMO称第2个变量的选择称为内循环。在找到第一个变量的基础上,第二个变量的标准是希望能使有足够大的变化。由于是依赖于|E1−E2|,为了加快计算的速度,所以选择|E1−E2|最大时的。
当E1为正时,那么选择最小的Ei作为E2;如果E1为负,选择最大Ei作为E2。
为了节省时间,通常为每个样本的Ei保存在一个列表中,选择最大的|E1−E2|来近似最大化步长。
SMO算法步骤总结:
1.初始化α,一般情况下令初始的αi全部为0;
2.选取优化变量α1和α2,执行相关的优化计算,得到更新后的α1,α2;
3.开始新的一轮迭代,重复执行上面的第2步,直到全部的αi满足公式(2)的KKT条件以及公式(1)中的约束条件;